Snehesh Shrestha, Yantian Zha, Saketh Banagiri, Ge Gao, Yiannis Aloimonos, Cornelia Fermüller
Perception and Robotics Group
University of Maryland College Park
Abstract
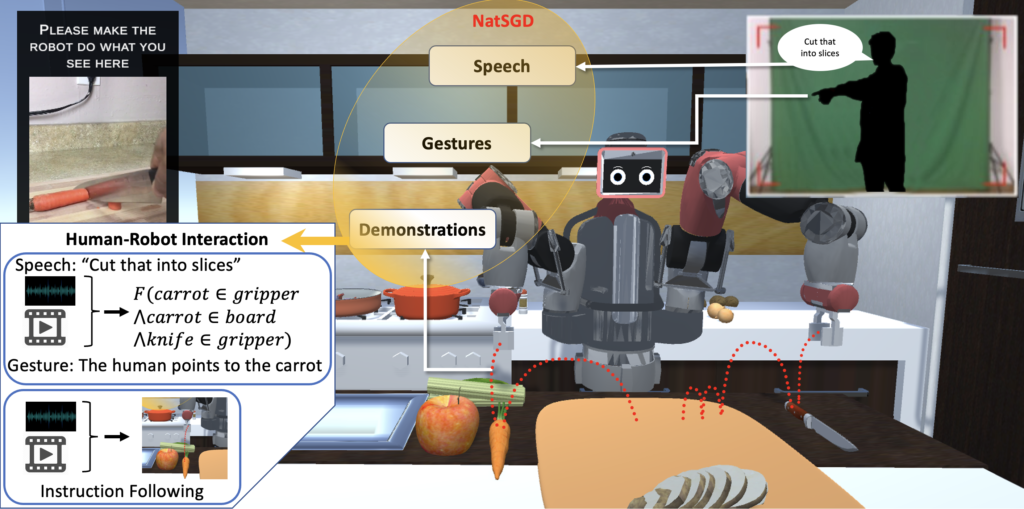
Recent advancements in multimodal Human-Robot Interaction (HRI) datasets have highlighted the fusion of speech and gesture, expanding robots’ capabilities to absorb explicit and implicit HRI insights. However, existing speech-gesture HRI datasets often focus on elementary tasks, like object pointing and pushing, revealing limitations in scaling to intricate domains and prioritizing human command data over robot behavior records. To bridge these gaps, we introduce NatSGD, a multimodal HRI dataset encompassing human commands through speech and gestures, synchronized with robot behavior demonstrations. NatSGD serves as a foundational resource at the intersection of machine learning and HRI research, and we demonstrate its effectiveness in training robots to understand tasks through multimodal human commands, emphasizing the significance of jointly considering speech and gestures. We have released our dataset, simulator, and code to facilitate future research in human-robot interaction system learning; access these resources at NATSGD website, paper, dataset and supplementary works.
This video is a short sample generated by playing back a demonstration trajectory from the NatSGD dataset. In this clip, the robot follows human instructions to cook a vegetable soup dish. It includes covering a pot of heated water and fetching an onion and a carrot. Each activity is guided by human speech, which is displayed (as closed caption texts) at the bottom of the screen. We also overlay gestures as images with skeleton key points in the middle of the video. The video is a mosaic of 8 different camera views and modalities. The top row shows camera perspectives from different angles. From left to right, the first view is a non-stationary camera view, which the human participant saw during the interaction. The other three are fixed cameras with third-person views. The bottom row cameras are the robot’s first-person view from the camera mounted on the robot’s head. From left to right, the first one is an RGB image. The second is a depth image. The third view is instance segmentation, i.e., color is assigned to each object of individual identity. The last view is a semantic segmentation where each color represents a single category, such as appliances, utensils, and food. The depth view gives the perspective of the shape of each object and how far they are. The instance segmentation helps the robot understand the boundary of each object and how they interact with each other. Finally, semantic segmentation helps the robot understand the common properties of objects belonging to each category and can help generalize beyond the dataset.
Below we use two examples to show why having both speech and gestures is important.
Example 1
From time 1 min 42 sec, the participant instructs the robot to fetch a single onion. The participant gazes at the onions behind the robot on the right side and says, “Baxter, we need one onion.” The phrase “one onion” implies the specific onion, and the gaze implies its general direction.
Example 2
Similarly, from 2 min 5 sec, the participant points to the countertop and potatoes, “Put it next to the potatoes.” This instruction implies between the potato and the apple, which the participant does not specify explicitly.
Results

Acknowledgments
We would like to thank peers and faculties from the UMD CS department and the Perception and Robotics Group for their valuable feedback and discussions. Special thanks to Vaishnavi Patil, Dr. Ge Gao, Lindsay Little, Dr. Vibha Sazawal, Dr. Michelle Mazurek, Nirat Saini, Virginia Choi, Dr. Chethan Parameshwara, and Dr. Nitin Sanket. We want to thank and recognize the contributions of Aavash Thapa, Sushant Tamrakar, Jordan Woo, Noah Bathras, Zaryab Bhatti, Youming Zhang, Jiawei Shi, Zhuoni Jie, Tianpei Gu, Nathaneal Brain, Jiejun Zhang, Daniel Arthur, Shaurya Srivastava, and Steve Clausen. Without their contributions and support, this work would not have been possible. Finally, the support of NSF under grant OISE 2020624 is greatly acknowledged.
Bibtex
@inproceedings{shrestha2024natsgd,
title = {{NatSGD}: A Dataset with {S}peech, {G}estures, and Demonstrations for Robot Learning in {Nat}ural Human-Robot Interaction},
author = {Snehesh Shrestha, Yantian Zha, Saketh Banagiri, Ge Gao, Yiannis Aloimonos, Cornelia Fermüller},
year = {2023},
}License
NatSGD is freely available for non-commercial and research use and may be redistributed under the conditions detailed on the license page. For commercial licensing or if you have any questions, please get in touch with me at snehesh@umd.edu.